
设计输入和实现
概述
Vivado™ 支持传统 HDL 中的设计入口,如 VHDL 和 Verilog。此外,它还支持一款基于图形用户界面的工具,称为 IP Integrator (IPI),其允许使用即插即用 IP 集成设计环境。
Vivado ML Edition 为当前复杂的 FPGA 和 SOC 提供一流的综合及执行方案,可针对时序收敛与方法提供内建功能。
Vivado 默认流程中提供的 UltraFast 方法报告 (report_methodology) 可帮助用户约束设计、分析结果并收敛时序。
功能
以下是 Vivado™ Design Suite 设计输入和实现功能的快速概述。点击其它标签,了解完整的特性详情。
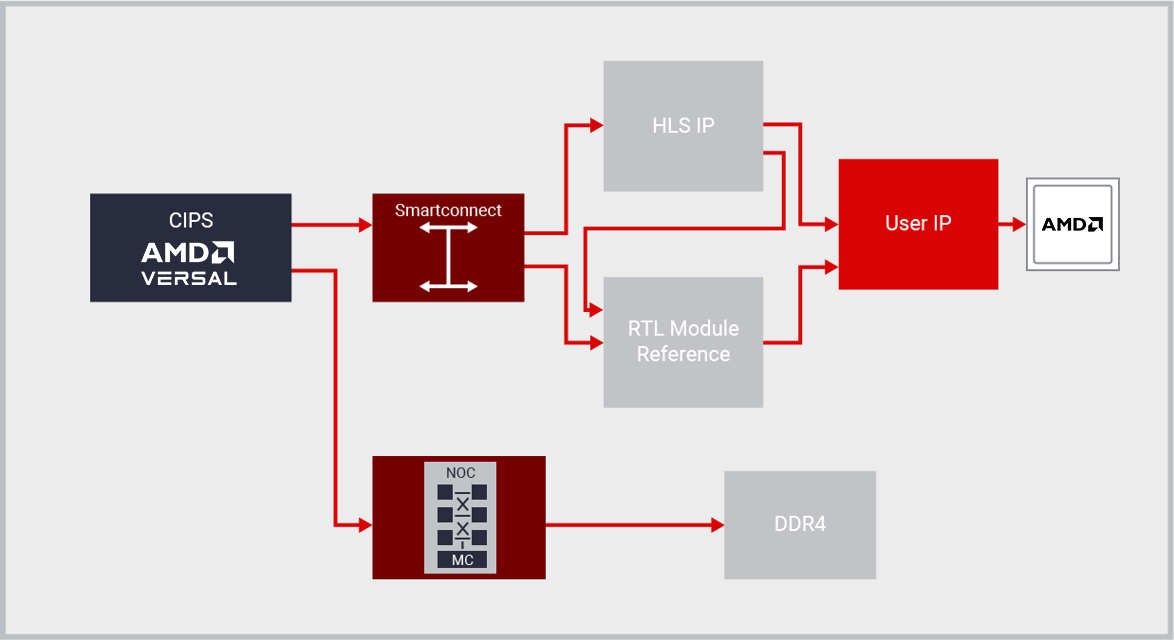
IP Integrator
Vivado™ ML 版可提供业界首款即插即用型 IP 集成设计环境并具有IP 集成器特性,从而解决了 RTL 设计生产力问题。
Vivado IP Integrator 可提供基于 Tcl、设计期正确的图形化设计开发流程。IPI 特性可提供具有器件和平台意识的互动环境,能支持关键 IP 接口的智能自动连接、一键式 IP 子系统生成、实时 DRC 和接口修改传递等功能,此外还提供强大的调试功能。
在 IP 之间建立连接时,设计人员工作在“接口”而不是“信号”的抽象层面上,从而大幅提升了生产力。 这通常采用业界标准的 AXI4 接口,不过 IP 集成器也支持数十个其它接口。
设计团队在接口层面上工作,能快速组装复杂系统,充分利用 Vitis HLS、Model Composer、AMD SmartCore™ 和 LogiCORE™ IP 创建的 IP、联盟成员 IP 和自己的 IP。通过利用 Vivado IPI 和 HLS 的完美组合,客户能将开发成本相对于采用 RTL 方式而言节约高达 15 倍。

Vivado IP Integrator 的主要特性和优势
- IP Integrator 层次化子系统在整个设计中的无缝整合
- 快速捕获与支持重复使用的 IP Integrator 设计封装
- 支持图形和基于 Tcl 的设计流程
- 快速仿真与多设计视窗间的交叉探测
- 支持处理器或无处理器设计
- 算法集成 (Vitis HLS 和 Model Composer) 和 RTL-level IP
- 融 DSP、 视、模拟、嵌入式、连接功能和逻辑为一体
- 支持基于项目的 DFX 流程
- 可在设计装配过程中,通过复杂接口层面连接实现 DRC
- 常见设计错误的识别和纠正
- 互联 IP 的自动 IP 参数传递
- 系统级优化
- 自动设计辅助
- 使用 Block Design Container 的基于团队的设计可实现可重用性和模块化设计
- 版本控制改进,将源文件与生成的文件分开
- 用于比较两个块设计的块设计差异工具
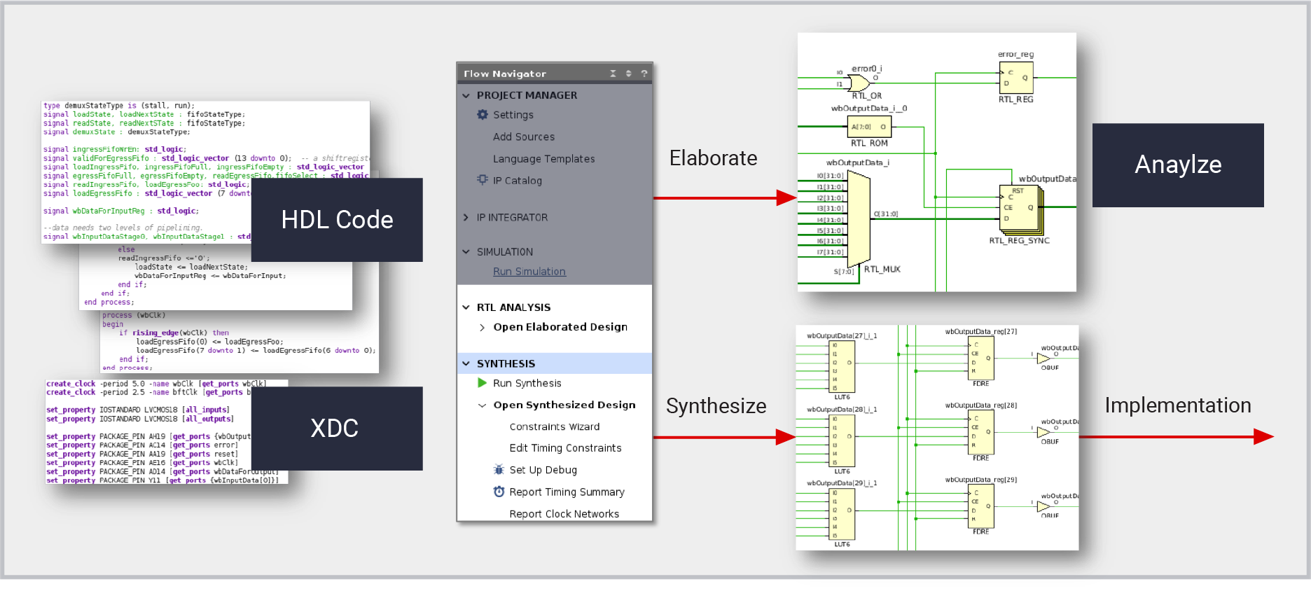
逻辑综合
Vivado 逻辑综合是一款创建设计的工具,可帮助硬件设计人员针对所有最新 AMD 器件创建最佳平台、IP 及定制设计。逻辑综合可将采用 SystemVerilog、VHDL 和 Verilog 编写的寄存器传输级 (RTL) 设计转换为库单元的综合网表,用于下游实现方案。考虑到目标技术,综合可以从 RTL 描述中推断直接映射至专用芯片结构的函数,包括 LUTRAM、Block RAM、位移寄存器、加法减法器和 DSP 模块等。综合结果可使用属性、工具选项和 Xilinx 设计约束 (XDC) 促进,以达到设计目标。逻辑综合在 Vivado 项目和 Tcl 脚本中运行,为生成 RTL 描述的其它高层次设计方法打下了坚实的基础,其中包括高层次综合和 IP Integrator 等。
逻辑综合引入机器学习,有助于加速编译。ML 模型通过预测设计的不同环节所需的综合优化来提高整体效率。

主要特性
逻辑综合支持符合行业标准的最新可综合构建:
- SystemVerilog、Verilog、VHDL 和 VHDL-2008 硬件描述语言 (HDL)
- 能够在相同的设计中混合不同的 HDL 类型,并将参数和通用类型传递给每种类型
- 语言模板,确保将推断出的复杂函数可靠地映射到适当的设备资源中
可使用交叉探测至相关 HDL 源代码的详细设计原理图,直观地查看 HDL 描述。
逻辑综合提供对推断和优化各环节的控制。分配可通过以下方式完成:
- 将工具和命令选项全局使用
- 在逻辑层级(使用 BLOCK_SYNTH XDC 约束)的特定模块或实例上
- 在使用 HDL 属性的单元及网上
控制类型包括:
- 保持、扁平化和重新构建层级
- 推断或不推断特定技术结构
- 选择用于映射内存阵列的专用内存资源的类型
- 为有限状态机 (FSM) 分配编码类型
- 为性能、利用率或功耗确定优先级
- 应用高级优化,如逻辑重定时
- 转换门控时钟,寄存启用信号
Vivado 逻辑综合支持所有层次的定制,从按钮操作到不同编译策略的探索,无所不能。
逻辑综合……
- 与 Vivado 项目和非项目流程协作
- 可以使用 Tcl 交互运行或在批处理模式下运行
- 运行多个流程,缩短编译时间
- 提供编译策略,探索针对不同设计目标的解决方案
- 支持增量编译模式,其可重复使用以前运行的数据,加速编译迭代
设计方法
与 Vivado 一起使用时,UltraFast 方法可帮助定义适当的约束,可帮助正确驱动工具并分析结果并可提高整体生产力。UltraFast 设计方法是一系列最佳硬件设计实践,这些最佳实践源于 Vivado 专家多年的经验以及他们在客户设计方面取得的可推动工具和技术发展的设计收敛成功。

主要特性
UltraFast 在各种用户指南中进行了广泛归档,包括:
- UG949,这是 AMD FPGA 和 SoC 的 UltraFast 设计方法指南,是一本面向电路板及器件规划、设计与约束创建、设计实现以及设计收敛的深度指南
- UltraFast 设计方法快速参考指南,是一份总共有两页的整体 UltraFast 方法的摘要,包括 UG949 所有章节的最重要规则和决议步骤
- UltraFast 设计方法时序收敛快速参考指南,是一份以 UltraFast 方法时序收敛为重的摘要,总共有 10 页,包括逐步分析和解决所有常见时序问题的程序,以及逐步分析和减轻布线拥塞的步骤。
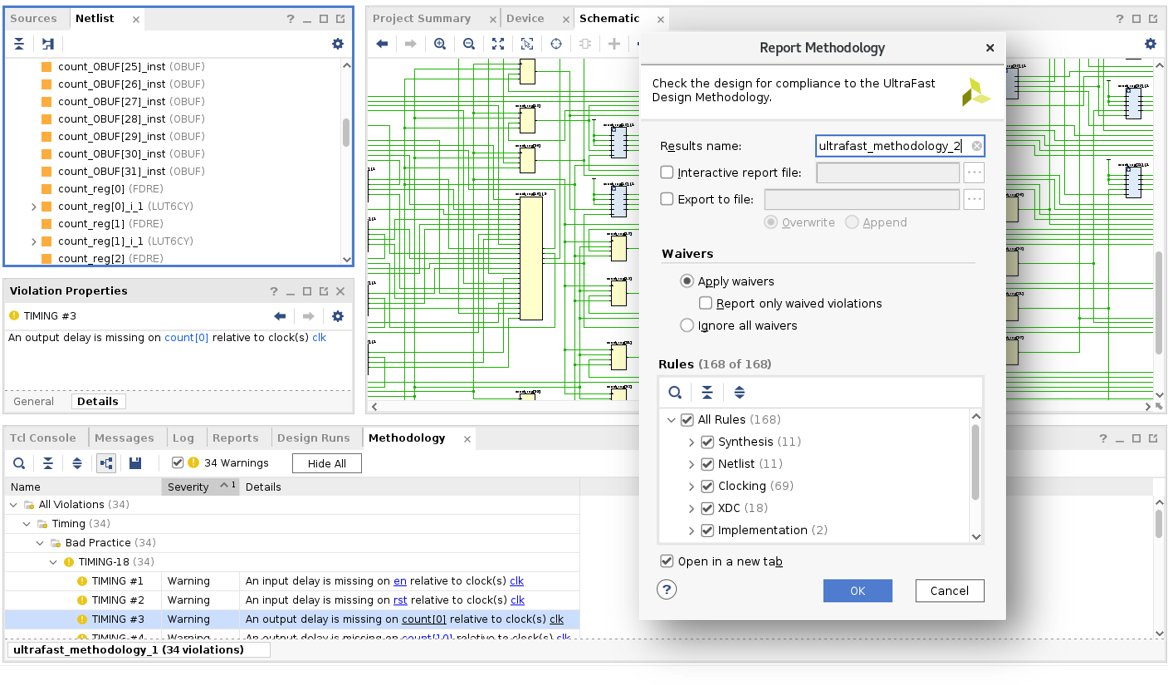
为了促进遵循 UltraFast 方法指导方针,UltraFast 方法报告内建在 Vivado 中,在默认情况下,针对 Vivado 项目生成,无需阅读任何文档,便可提供 UltraFast 优势。报告方法特性可生成一个在当前设计中发现的方法违规列表,按类别和严重程度进行分类,以便对照查看。查看并处理方法违规,可确保为设计的实现提供最佳起点,从而可在最短的时间内为设计的成功收敛提供最大的可能性。可以放弃被认为可以接受的违规,使其不再出现在报告中。
提供完整、正确的约束是 UltraFast 方法的重要组成部分。时序约束向导 (TCW) 不仅可分析时序约束,而且还可为提供缺失约束以及修复无效约束提供分步指导。约束完整性可降低不受约束的时序路径导致硬件漏洞的几率,而无效约束则会将编译工作误导为错误的时序临界。
功耗约束质量是功耗精确分析的关键。功耗约束顾问可分析设计切换活动,可精确找到似乎错误指定的区域,并可生成全方位 XDC 功耗约束,进行适当分析。Vivado 功耗报告还包括一个置信水平,指示低、中、高质量的功耗约束规范,从而提供有关功耗约束完整性的反馈。高置信水平可确保最精确的功耗分析,从而能与硬件测量紧密匹配。
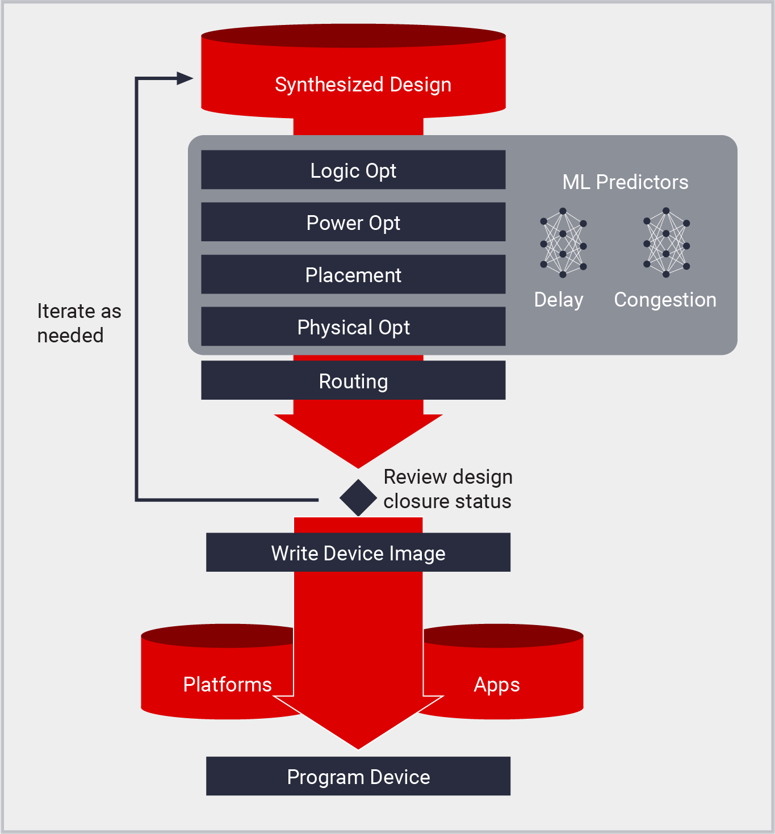
实现方案
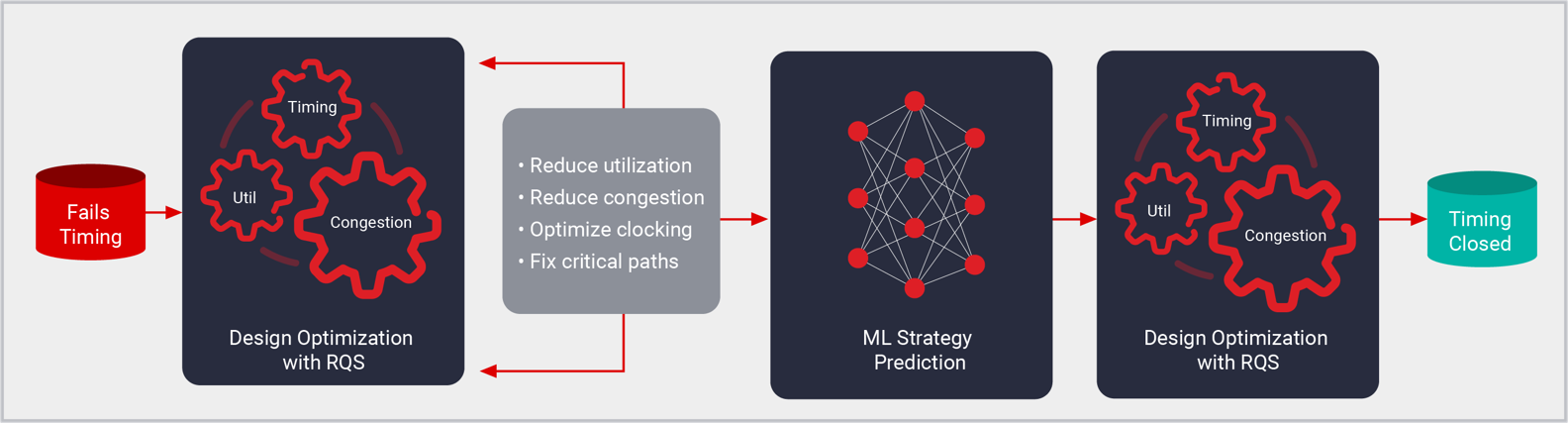
Vivado 实现方案是 AMD 器件的布置与布线工具,可通过综合网表生成比特流与器件图像。该实现方案支持创建各种尺寸的平台和定制设计,从最小的 MPSoC 到最大的单片及堆叠硅片互联 (SSIT) 器件(包含数百万个逻辑单元),无所不包。Vivado 实现方案建立在业界一流分区、布置与布线算法基础之上,这些算法由基于机器学习的预测器指导。ML 模型的应用允许实现方案通过准确预测布线延迟与拥塞,在更短的时间内实现更高质量的结果 (QoR)。实现方案由 Xilinx 设计约束 (XDC) 驱动,可达到在 Vivado 项目和 Tcl 脚本中性能、利用率以及功耗和综合工作的设计目标。
实现方案支持所有工作模式,从易于使用的按钮模式到用于处理性能要求最严格的设计的高级定制 Tcl 方案,无一例外。时序、利用率、功耗以及其它设计质量指标的详细分析均可在任何编译阶段执行:布置前、布置后以及布线后。此外,还可使用设计检查点 (DCP) 文件在任何编译阶段保存和恢复设计数据库,并可相应查看和约束设计。

主要特性
实现方案包括以下流程:
- 逻辑优化:综合后,逻辑网表在全局层面上进一步优化,以降低利用率并减少逻辑层次。
- 功耗优化:使用工作门控技术降低设计功耗,无需干预,不改变功能性,而且几乎不会影响时序。
- 布置:逻辑网表单元按照 XDC 限制(包括时序、平面布置图和手动布局要求)布置在物理器件资源中。布置从布置资源开始,包括 IO 和时钟资源以及基于设计层级的逻辑集群。在全局布置阶段之后是详细布置阶段以及布置后优化阶段布置由预测布线延迟和预测布线拥塞的 ML 模型指导,与传统统计方法相比,其可提供更高的准确性和更快的编译速度。
- 布线:网表组件间的连接分配给物理器件互连资源。与布置类似,布线从 IO 和时钟等全局资源开始,然后根据 XDC 时序约束对资源分配进行优先级排序。布线的最后阶段将进一步优化布线,以满足签名设置及保持的需求。在布置过程中使用 ML 布线拥塞预测,减少布线拥塞。
- 物理优化:物理优化是一个由时序推动的流程,贯穿整个布置和布线过程。与逻辑优化不同,物理优化使用根据布置与布线提供的最精确的时序数据。对时序影响进行评估,这样只有执行的优化才能得到改进的时序。优化技术包括复制、重新定时和寄存器更换,以及其它针对目标架构的优化。此外,物理优化还可在布置后和布线后分别运行,以进一步改善结果。
设计可以在实现过程中的任何编译阶段执行分析。分析功能的核心是:
- 综合 XDC 约束管理系统,允许修改并验证时序、功耗及物理约束。
- 报告时序摘要:一个强大的静态时序分析器支持 XDC 约束,以帮助实现方案达到指定的时序目标。为重要的时序路径、时钟交互和时钟域交叉 (CDC) 生成时序报告。
- 报告功耗:无矢量传播可为功耗分析提供 XDC 开关工作支持。生成报告,识别较高功耗区域。
- 器件视图:设计布置与布线的图形表示以及逻辑网表原理图。可在物理、逻辑和源代码设计视图之间实现交叉探测,从而可快速跟踪重要时序路径的来源。
Vivado 实现方案支持所有层次的定制,从按钮操作到为要求难以满足的设计探索不同编译策略与迭代流程,无所不能。
实现……
- 与 Vivado 项目和非项目流程协作
- 可以使用 Tcl 交互运行或在批处理模式下运行
- 运行多个线程,缩短编译时间
- 提供编译策略,探索针对不同设计目标的解决方案
- 支持增量编译模式,其可重复使用以前运行的数据,这可以优先考虑编译加速,也可以优先考虑时序收敛




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}